Protecting Packet Tracer Myself Because No One Gives a F*ck19/02/2021
In my previous blogpost, I have discussed how students are able to exploit Packet Tracer to cheat their exams. You may have to read the article first before you continue, the article explains how the Packet Tracer software can be exploited and gives advice on how to prevent such techniques. The point is that Cisco, the company behind the Packet Tracer software, just doesn't seem to care at all how good or bad the software is secured.
My previous blogpost on Packet Tracer has been sent to Cisco, and at the time of writing, there wasn't any response. So this leaves educational institutions with a big problem, a problem that can only be solved by the original software developers (Cisco)?
No, Thanks to reverse engineering, we can figure out how the Packet Tracer software works, and then modify the Packet Tracer binary to work in a way we want! The goal of this article is to improve Packet Tracer by making it more secure without the need for its source code.
NOTE: Cisco has responded to me after I had written this article. I had someone more professional help me the second time I contacted Cisco.
My Story
Unfortunately, I have recently been expelled from school for developing a Packet Tracer Password Recovery tool, the school considered that my tool was an attempt to fraud exams. Not only my own exams, but they also accused me of helping thousands of other students to fraud their exams. Even tho there was no proof of me actually using the software on any exam... They then asked me the following question, "Can Packet Tracer still be used to provide a fair exam?", and the answer to that question is... well... you will able to answer yourself after reading the whole article.
The Plan
With that question in mind, using the original Packet Tracer software was a no go, the software has no obfuscation, no anti-debugging, no nothing (not even ASLR). To improve the security of the software, we have to implement all of those features so we can prevent as much hacks as possible in the future. Sounds impossible without the source code? well, how about developing a DLL that gets called by Packet Tracer at startup? or a loader that manually maps Packet Tracer into memory and then scans memory regions to check if anyone attempted to modify code?
Those are all great ideas, they greatly improve security but there is one thing that's missing, there is no key component that forces a student to use the modified version... There must be something that forces a student to use our own specific version of Packet Tracer... and that should be... the file format! Yes, with the .pka file format, we can force students to use a specific version. Any of you boomers remember Packet Tracer version 5? Good luck using version 5 .pka files in the new version 7. Spoiler alert, when you do, Packet Tracer throws an error, showing that your .pka file format is outdated.
The Actual Plan
So what we have to do is figure out how a .pka file works exactly and create our own version. It is important for us that we can unpack the original .pka file so we can then re-pack an existing .pka file to our own format. Once we have our own format, we have to patch our secure version of Packet Tracer and replace the original unpacking algorithm with our custom one. The replacement of the algorithm can be done by modifying the original algorithm just enough so it will no longer accept original .pka files.
We can go all crazy here by using a custom DLL to hook the original algorithm and use a more complex algorithm, but for today I will just show a basic, 'good enough' example.
The benefit is that our 'magic' algorithm is private, and the software containing the magical algorithm is only handed out to students of the educational institution. Therefore making it impossible for students to use existing tools that target the original version of packet tracer. Not only do we prevent public known tools (for example), but we can also reduce the lifetime of new tools by regularly updating the 'magic' algorithm to force a cat and mouse game between educators and students.
NOTE: Version 7.3 and above have ASLR enabled, this research was done on version 7.2.1.
Reversing the activity file format (.pka)
First things first, before we can start implementing our own magic algorithm, we need to reverse-engineer the current algorithm that is used to encode/decode the .pka file format. Thanks to my previous blog post I already have a good knowledge of what Packet Tracer is made of. One of the noticeable things is that it uses the Qt5 framework to handle strings and files.
Looking for 'File'
The first thing I did was throw the Packet Tracer binary into IDA and look at the import table, mainly looking for the Qt5 import functions. While doing that, I made use of IDA's search feature so it will only show me a list of functions that contain a given string in their name. Since I know that Packet Tracer will use some kind of function to read the .pka file, I simply started looking for functions containing "Open", "Read", "Stream", "File", etc in their name.
Looking into all of those functions will be time-consuming, have a look at the image above to get an idea of how many results I got. Therefore I am only interested in the constructors of a given class, because, all I want to know (for now) is if Packet Tracer is actually using that class or not. Packet Tracer has to call the constructor at least once to create the object, therefore I did a quick xref to find out if the function was used by Packet Tracer. Now I should have an idea of which classes Packet Tracer is using, and it's time to fire up Cheat Engine.
Once Cheat Engine is open, it's time to breakpoint the constructor functions and load in a .pka file. My breakpoints are placed on all variants of the QFile::File function, time to load in a .pka file and see what happens.
Let's not waste too much time here, after my breakpoint got triggered I checked the stack and wrote down three functions that are coming from the Packet Tracer base image. I then threw them all three into IDA to have a quick look at what they do, and based on their Qt5 function calls and string references, it seems that the two of them were used to warn the user that he may lose progress in his current file by loading in the new .pka file. That means we can throw those two in the garbage and focus on the one we have left.
Single steps
Alright, back to the one function that has the real sauce in it, I opened the function in IDA and breakpoint the start of the function in Cheat Engine. By looking at the IDA graph I can have a better look at the control flow while I single-step through the assembly code using Cheat Engine debugger. The below image shows the control flow of the function we are analyzing.
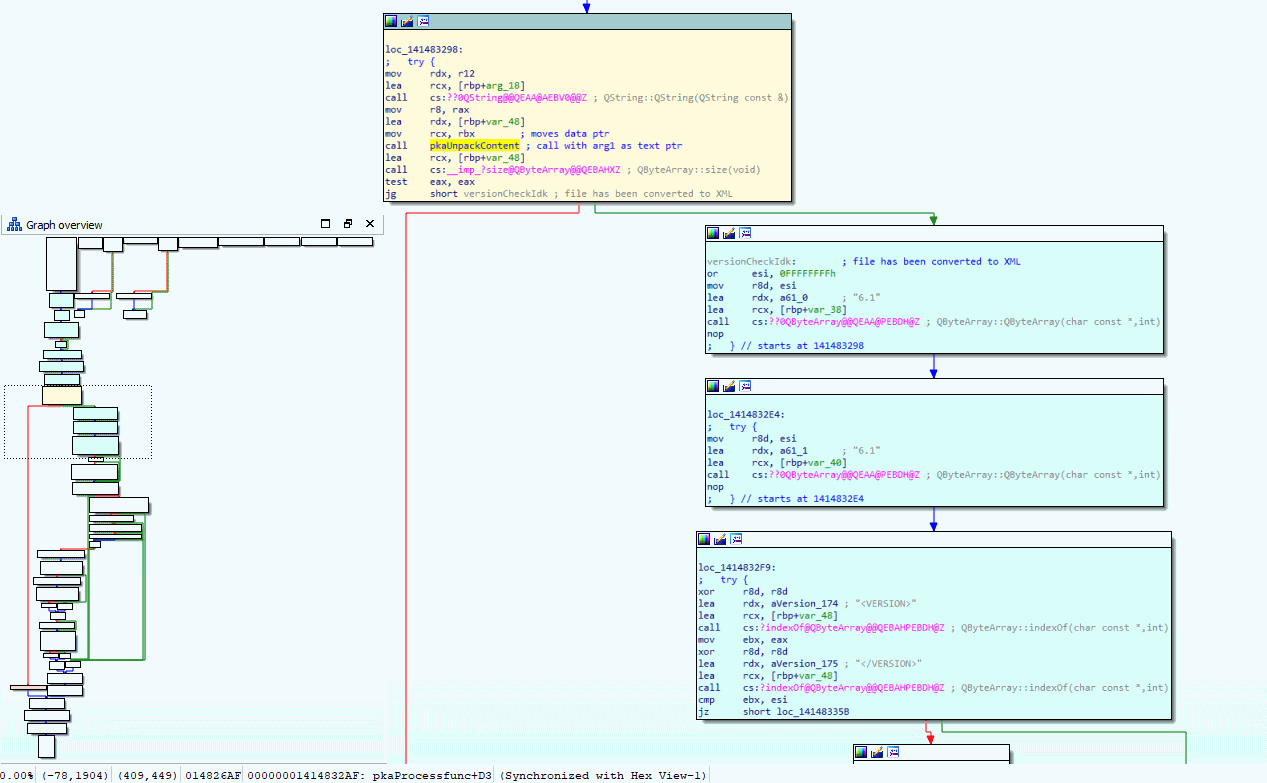
Have a close look at the yellow block, it calls the constructor to create a Qt5 string, then calls an unknown function (spoiler alert, its pkaUnpackContent), calls to get the size of a QByteArray object, and then jumps to the blue blocks if the size is not zero. Looking a bit further in the blue blocks you can see it is referring to string <VERSION> and </VERSION>, so to me, it looks like the XML got unpacked at that point. Spoiler alert, I gave the 'unknown' function the name 'pkaUnpackContent' so you may have already guessed the magic happens in there.
But the real question is not where it happens, it is how it happens! To figure these out, let's have a look at the function pkaUnpackContent in IDA's graph view.
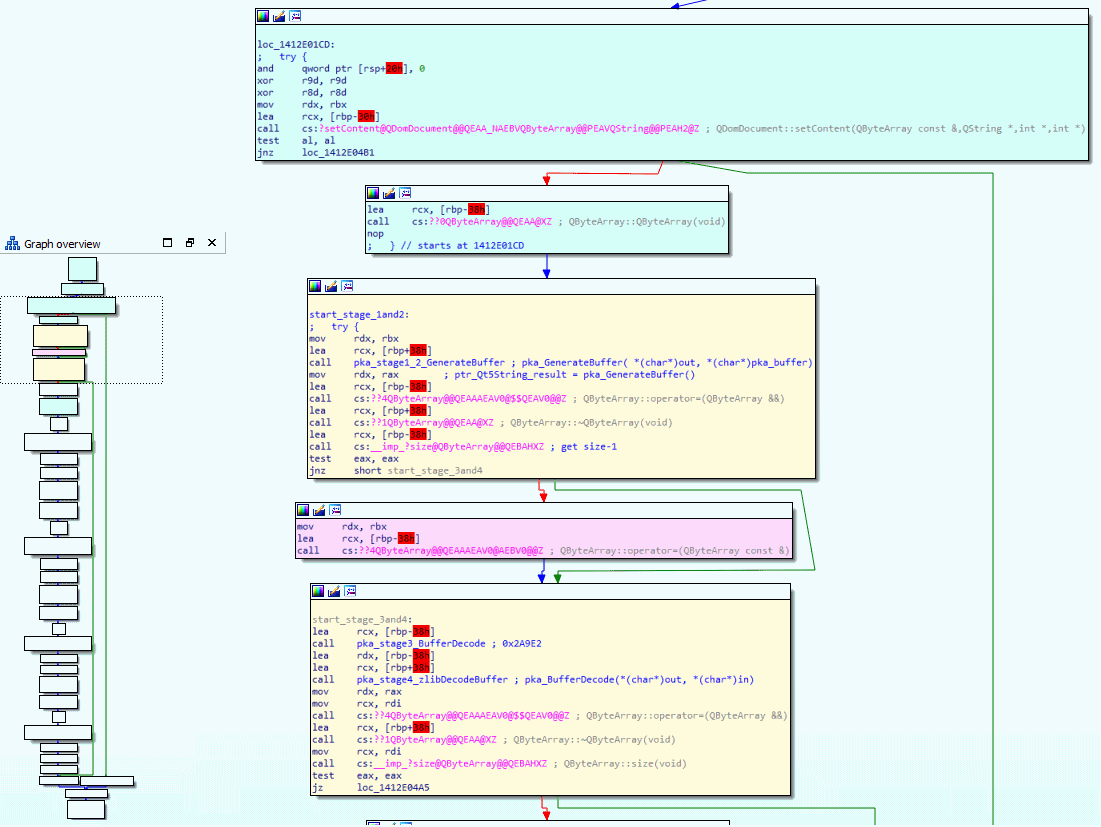
Again, I have analyzed the function and cut out the boring stuff. You can see the full control flow for pkaUnpackContent in the lower-left corner and then the useful blocks are zoomed into. I debugged the function by single-stepping through it and then watching which arguments get feed into the function and what comes out of it by keeping a close look at the buffer holding the raw .pka bytes, I then noticed that the buffer changed after it executed the yellow blocks in the above screenshot. Oh and because the two yellow blocks you see are responsible for doing the four stages of decoding, meaning we got again a little step closer to our goal. So close that we can almost see the stages.
The Stages of Decoding
After single stepping and keeping a close eye on the heap, we have managed to find multiple functions that are responsible for manipulating data that was originally coming from the raw .pka file. Therefore I will go into each function in greater detail and describe how I reversed every single assembly instruction of them, or at least, the instructions that are relevant to the decoding process. Below is the list of stages that we will be looking into.
Oh and... I have found a GitHub repository online that was capable of unpacking version 5.x of the file format. According to that repository they only used stage 1 and stage 4 of the above encoding/decoding stages in version 5.x. This means that Cisco is actually taking action against people like me, which is a good thing to see!Stage 1: Reverse Xor
Alright, if you remember the last screenshot, you will see that there is a function named pka_stage1_2_GenerateBuffer, and you probably guessed it, it is responsible for decoding both stage 1 and 2 of the buffer. The control flow of the image is shown below
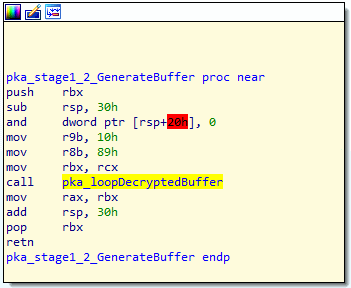
There is not much going on here, other than passing a few hardcoded arguments to another function call. I have named the function that gets called pka_loopDecryptedBuffer, the control flow of that function can be found in the image below.
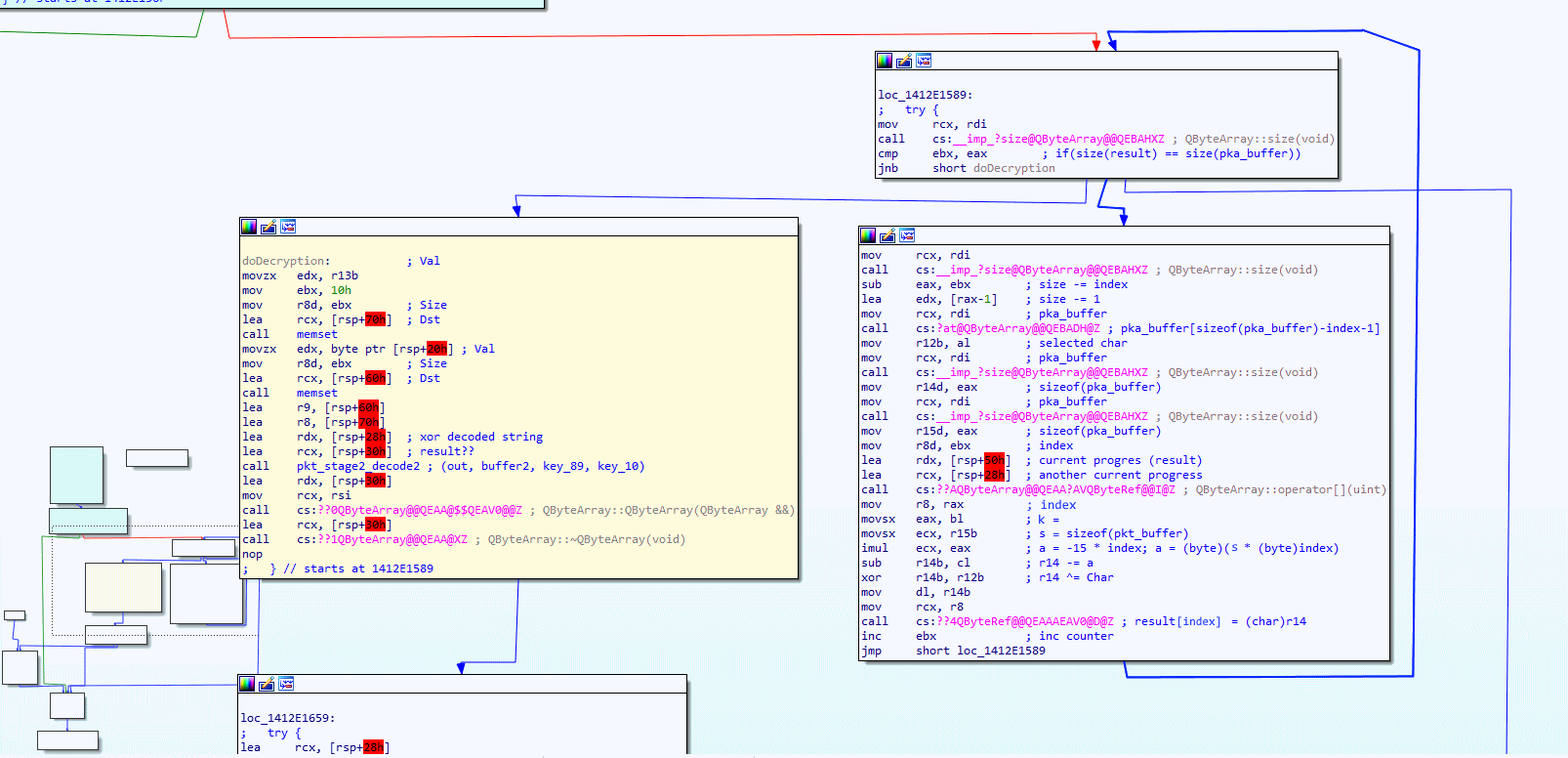
Now have a look at the two pink blocks (mouseover/tap image to zoom in), surprise surprise, it seems to be a loop, and if you look at the end of the second pink block, you also able to see an XOR assembly instruction. The two pink blocks are the first stage of decoding, they do XOR, starting with the last byte in the array while using the length of the buffer to create the key. Please have a good look at the two pink blocks and take a deep look at the assembly instruction before you continue reading.
Think you understand what's going on? then it is time to show you my C# code that I wrote to re-create the reverse XOR decoding. The below function unpackStageOne should give you a better understanding of what the assembly xor was doing.
private bool unpackStageOne() { byte k = (byte)this.Buffer.Length; int s = this.Buffer.Length; for (int i = 0; i < this.Buffer.Length; i++) { byte ch = this.Buffer[this.Buffer.Length - i - 1]; byte a = (byte)(k * (byte)i); byte c = (byte)(this.Buffer.Length - a); c ^= ch; this.Buffer[i] = c; } return true; }
Stage 2: Pump it up
Stage 2 is a bit different. What happens here is Packet Tracer is using a library called Crypto++ to pump the buffer through a pipeline with the TwoFish filter, which basically means it is decrypting it using the TwoFish block cipher algorithm. The algorithm gets invoked with a key and an initialization vector, have a look at the table below for the key/IV you need.
| Action | File Info | Key | IV |
|---|---|---|---|
| Decrypt Encrypt |
Packet Tracer Acticity (.pta) | ABABABABABABABABABABABABABABABAB |
CDCDCDCDCDCDCDCDCDCDCDCDCDCDCDCD |
| Decrypt Encrypt |
PKC Files (.pkc) | ABABABABABABABABABABABABABABABAB |
23232323232323232323232323232323 |
| Decrypt Encrypt |
Log Files | ABABABABABABABABABABABABABABABAB |
BEBEBEBEBEBEBEBEBEBEBEBEBEBEBEBE |
| Decrypt Encrypt |
Log Files | BABABABABABABABABABABABABABABABA |
BEBEBEBEBEBEBEBEBEBEBEBEBEBEBEBE |
| Decrypt Encrypt |
Packet Tracer Saves | 89898989898989898989898989898989 |
10101010101010101010101010101010 |
| Decrypt Encrypt |
Unknown_1 | 12121212121212121212121212121212 |
FEFEFEFEFEFEFEFEFEFEFEFEFEFEFEFE |
| Decrypt Encrypt |
Unknown_2 | F1F1F1F1F1F1F1F1F1F1F1F1F1F1F1F1 |
1F1F1F1F1F1F1F1F1F1F1F1F1F1F1F1F |
NOTE: Extracted from PacketTracer v7.2.1
For the code, I have forked a TwoFish C# implementation from github and used it like this:
public bool unpackStageTwo() { // We use the 'Packet Tracer Saves' key, which works on .pka, .pkt and a few more I guess. Twofish twofish = new Twofish() { Mode = System.Security.Cryptography.CipherMode.CBC, Key = new byte[] { 0x89, 0x89, 0x89, 0x89, 0x89, 0x89, 0x89, 0x89, 0x89, 0x89, 0x89, 0x89, 0x89, 0x89, 0x89, 0x89 }, IV = new byte[] { 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10, 0x10 } }; ICryptoTransform decrypt = twofish.CreateDecryptor(); System.IO.MemoryStream msD = new System.IO.MemoryStream(); CryptoStream cryptostreamDecr = new CryptoStream(msD, decrypt, CryptoStreamMode.Write); cryptostreamDecr.Write(this.Buffer, 0, this.Buffer.Length); cryptostreamDecr.Close(); byte[] tmp = msD.GetBuffer(); Console.WriteLine(tmp.Length); for (int i = 0; i < this.Buffer.Length; i++) this.Buffer[i] = tmp[i]; return true; }
Stage 3: Another Xor
Stage 3 is located in the second yellow block that was found in the pkaUnpackContent() when we were single-step debugging. Our pka_stage3_BufferDecode() function is a bit similar to stage 1 reverse XOR decoding, except this time it is not in reverse.
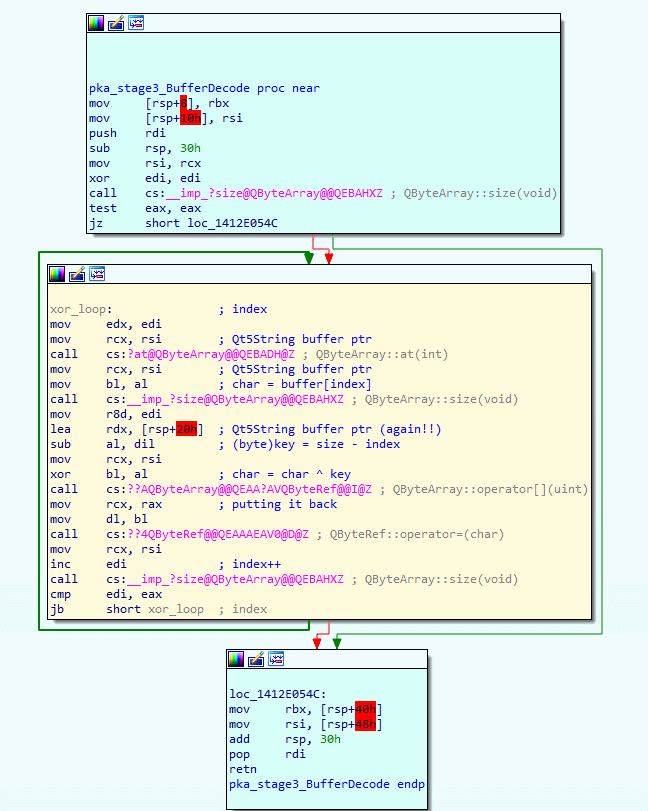
Since the XOR decoding is similar to the stage1 reverse XOR decoding, I won't go into any detail. Feel free to pause for a brief moment and have a good look at the yellow block where the XOR decoding happens. Once again, this XOR decoding loop iterates through all bytes of the buffer, this time from start to end, and uses the length as key.
The below code is my C# version of the stage 3 XOR decoding, have a close look at the code to get a better understanding of what the above assembly code was doing exactly.
private bool unpackStageThree() { for (int i = 0; i < this.Buffer.Length; i++) { byte ch = this.Buffer[i]; byte key = (byte)(this.Buffer.Length - i); ch ^= key; this.Buffer[i] = ch; } return true; }
Stage 4: Decompressing
Okay, I am not gonna lie, I did look into the Github repository that unpacked the file format for version 5.x. The Github repo stated that the first 4 bytes of the buffer indicated the length of the unzipped content, and that zlib was used to unzip the remaining buffer. In my defense, zlib has multiple formats. So I actually had to find the magic bytes myself and check which type of zlib was used. According to this list of file signatures from Wikipedia, I figured that my magic bytes ``78 9C`` stands for zlib 'Default Compression'.
After looking that up it was just a matter of googling for a C# NuGet to find a C# library that has all of the functionality I need from zlib to do the default compression. The C# function I created for unpackStageFour(), which decompresses and serializes the decompressed XML string to an object is shown below.
private bool unpackStageFour() { this.XmlContent = new byte[(this.Buffer[0] * 0x1000000) + (this.Buffer[1] * 0x10000) + (this.Buffer[2] * 0x100) + (this.Buffer[3] * 0x1)]; // first 4 bytes are size var zlibdata = this.Buffer.ToList(); zlibdata.RemoveRange(0, 4); // check for zlib 'Default Compression (no preset dictionary)' if (zlibdata[0] != 0x78 && zlibdata[1] != 0x9C) return false; // invalid header - https://en.wikipedia.org/wiki/List_of_file_signatures InflaterInputStream inflate = new InflaterInputStream(new MemoryStream(zlibdata.ToArray())); inflate.Read(this.XmlContent, 0, this.XmlContent.Length); // patch invalid character 0x03 for (int i = 0; i < this.XmlContent.Length; i++) if (this.XmlContent[i] < 0x09) this.XmlContent[i] = 0x3F; // ASCII questionmark this.xmlSerializer = new XmlSerializer(typeof(PACKETTRACER5_ACTIVITY)); this.Content = (PACKETTRACER5_ACTIVITY)this.xmlSerializer.Deserialize(new MemoryStream(this.XmlContent)); return true; }Also note that I 'patch invalid character 0x03' since the C# XmlSerializer doesn't like that character, therefore I simply replace that character with 0x3F, which is the question mark character in the ASCII table.
It's an XML!
Finally, we have reached plain text, which seems to be XML. This explains why Packet Tracer was referring to the strings <VERSION> and </VERSION> right after it successfully unpacked the file data. From now on we can use the C# functions we have made to fully unpack our original .pka files.
Custom algorithm
Now that we completely understand how Packet Tracer unpacks the .pka file type, we can start modifying the algorithm just enough to have custom .pka file versions. To keep it simple, I will simply modify stage 1 and replace the Xor key with a hardcoded key. This also means we have to re-pack our existing .pka files to convert them to our new format, I will create a tool that unpacks our existing .pka files and packs then using the slightly modified algorithm.
Patching original algorithm
Time to patch the stuff in IDA, in the image below you can see I have replaced a bunch of instructions with NOP and then pushed the XOR key (0x42) into the r14 register. Since we hardcode the XOR key we no longer need the function calls that obtain the size of the array, this means we can clean up a little bit of space. Have a close look and you can see that I have removed a total of 37 bytes, this may not sound like a lot, but know that setting our hardcoded XOR key costs only 4 bytes. This means there is plenty of room to make a more complex XOR algorithm, but for now, let's keep it simple and stick to the hardcoded XOR key example.
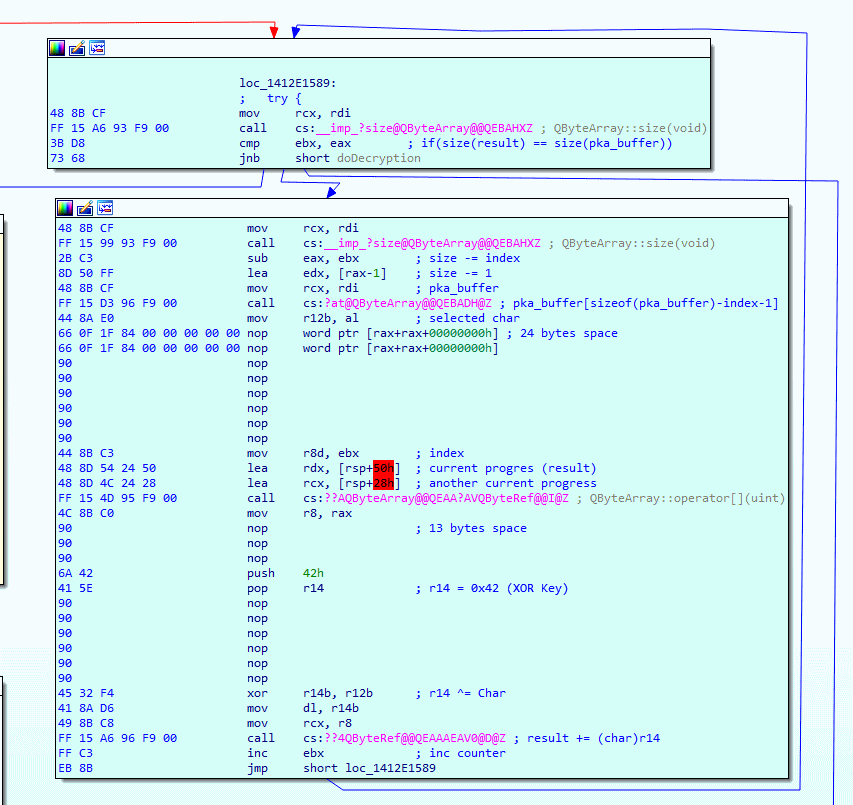
After that's done I decided to give it a go, and... it crashed. When I start Packet Tracer, I am greeted with an error message, so I decided to throw the original Packet Tracer binary into x64dbg so I can breakpoint stage 1 of the unpacking algorithm. It turns out that the function is called at startup, I get exactly 83 hit counts on the breakpoint, which seems like Packet Tracer is unpacking 83 files at startup?
After analyzing the files that got unpacked I figured out that Packet Tracer uses this algorithm for more than just .pka files, basically all files with the .ptd and .pts extension that are located in the Packet Tracer directory get unpacked and loaded into memory using the same unpacking algorithm at startup. This makes my job a little harder, it means we not only have to re-pack our .pka files, but also a bunch of other files that come with the installation of Packet Tracer. Fear not, because my set of tools to automatically do this is located on GitHub.
Re-packing pka files
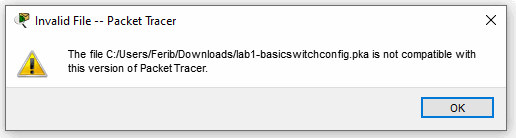
Finally, we have to re-pack our existing .pts, .ptd and .pka files. When we don't convert the .pts and .ptd files that are located in the Packet Tracer directory, we get the crash I just described. When a user uses a .pka file that is either, not re-packed to our current version or tries to use our re-packed .pka file in the original (and more vulnerable) Packet Tracer then this error will show up.
The result
You may have got a little confused with what we have done so far, therefore I created a visual representation of what I have achieved in my PoC. Have a look at the image below, on the left side you will see the original flow of Packet Tracer, and on the right side is our patched version.
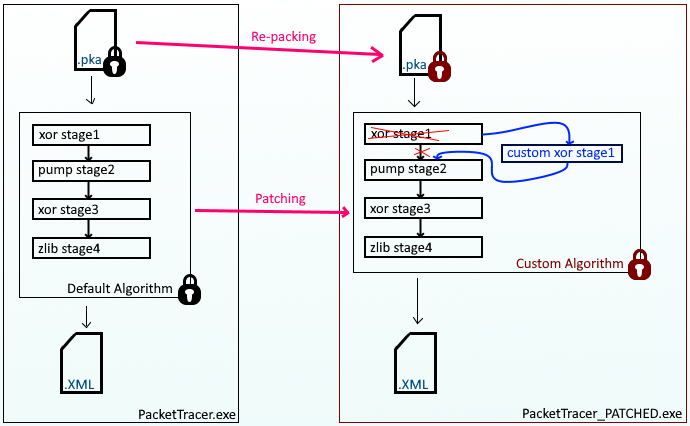
The purple lines represent the following actions that come from my PkaWizard toolset:
- Re-packing functionality is used to convert an original .pka file to a custom encoded version (or vise versa)
- Patching functionality is used to patch a custom algorithm inside an original PacketTracer binary (or vise versa)
Last but not least, a visual demonstration of my PkaWizard toolset.
- 00:04 - Original Packet Tracer using original file while opening original .pka
- 00:25 - Patched Packet Tracer using original files
- 00:44 - Patched Packet Tracer using patched files
- 00:52 - Patched Packet Tracer opening original .pka
- 01:14 - Patched Packet Tracer opening custom .pka
Conclusion
Nothing is 100% secure, especially when it is all client-side on a device that is not owned by you. The best way to prevent fraud using such tools is to update the software frequently, making it more time consuming for others to break it. Reversing the whole unpacking tool took me about 10 hours of works, which, may not sound that bad, but do know that people with such a skillset are charging over 100$ hourly rates. But yeah, I am just a bored college student that got a few extra months of vacation, waiting for the new school year to begin ;).
Download
For those who didn't find a link yet, here is the GitHub link to my PkaWizard project.
Consider giving a star to pump my dopamine levels for a split second!